vmcrawl
vmcrawl is a Mastodon-focused version reporting crawler. It is written in Python, with a Postgres database backend. It performs periodic polling of known Mastodon instances.
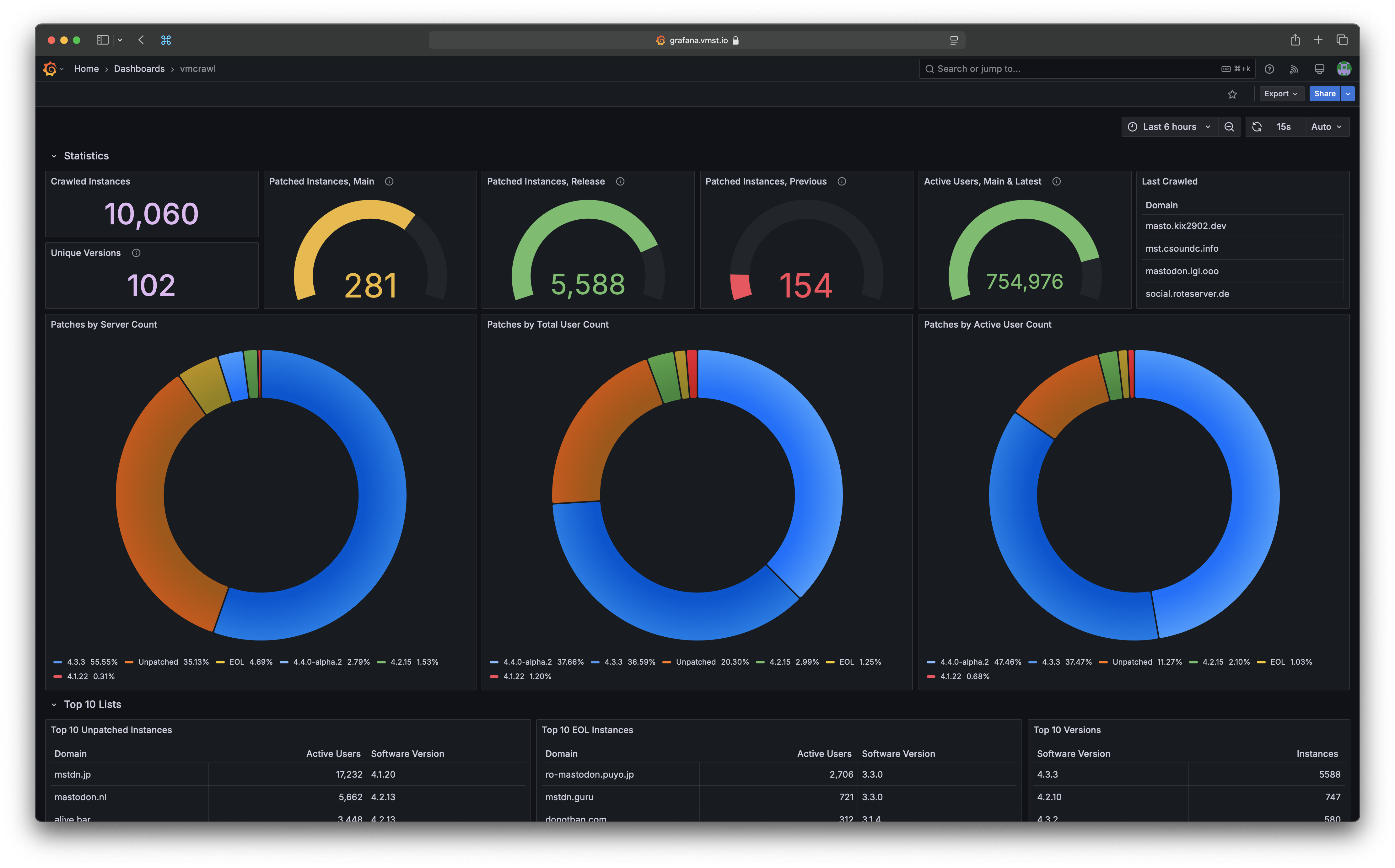
Crawled Endpoints
vmcrawl may attempt to access the following endpoints of your Fediverse server:
/robots.txt/.well-known/webfinger/.well-known/host-meta/.well-known/nodeinfo
Based on those results, if it's determined that your server is running Mastodon, it may access:
/api/v2/instancefor Mastodon 4.x/api/v1/instancefor Mastodon 3.x
vmcrawl may periodically attempt to access the following endpoint from known deployments:
/api/v1/instance/peers
User Agent
The vmcrawl user agent can be identified as: vmcrawl/0.x (https://docs.vmst.io/projects/crawler)
robots.txt
If you would like to stop vmcrawl from checking your instance, you can add the following to your robots.txt file:
User-agent: vmcrawl
Disallow: /
It will also respect a disallow of all bots/crawlers in this file, or an HTTP 410 reply to any endpoint.
Collected Data
vmcrawl collects the following data only from instances that it identifies as Mastodon, or a related fork:
- Software Version
- Total & Active Users Count
- Administrator Address
- Code Repository
vmcrawl may periodically request a list of peer instances from a server, but only to discover new servers to request the data outlined above. It does not store specific peer information for any server.
Uncrawled Instances
Some instances may not appear in our results based on many factors:
- Instances may opt-out of
vmcrawlby blocking our user agent specifically, or that block any crawler - Instances which appear on the IFTAS DNI list, are not interacted with
- Instances under known junk domains, which can be found here, are skipped
- Instances which do not allow unauthenticated access to their public instance API (as shown above) cannot be included
- Instances running versions of Mastodon prior to 3.0 lack the proper APIs, and cannot be included
- Instances which report suspiscious user counts (ex: active users larger than total users) are not included
- Instances which report distorted version information