Infrastructure
Introduction
The purpose of these documents is to provide an overview of the infrastructure used to operate the Mastodon server, vmst.io. It should explain how the various services interact and how "the magic" happens when our users open the Mastodon app on their phone or enter our address into their web browser.
It should also help provide some assurance to our current and potential members that care has been taken in architecting and operating this Mastodon instance.
Architecture Goals
- Provide better than 99.9% availability each month for our users.
- All critical components should be easily recoverable in the event of failure.
- Be easily scalable, both vertically and horizontally.
- Provide a highly performant experience for our users.
- Don't operate what we're not best suited to operating.
- Automate as much as possible for upgrades to enable the fastest time to implementation.
- Maintain a stable endpoint on the ActivityPub network.
Layout
Core Services
DigitalOcean is our primary hosting provider. We have workloads and data hosted in the TOR1, NYC3, and SFO3 data centers. Toronto is the home of our primary computing workloads, while New York is used for object storage hosting of the media CDN and documentation site. San Francisco houses regular backups while an additional replicated copy is located in Kansas City.
Service Providers
This list represents the cloud provider dependencies to which vmst.io has a direct relationship. If any of these providers have issues, it may create issues for vmst.io services. Some of these services are paid for, while others are free to use.
| Vendor | Service |
|---|---|
| DigitalOcean | Managed PostgreSQL, Managed Kubernetes, Managed Valkey, Managed OpenSearch, Object Storage, Content Delivery Network (CDN), Load Balancer, Internal Container Registery, and Nameservers |
| AWS | Simple Email Service |
| BetterUptime | Status Monitoring |
| DNSimple | Domain Registrar |
| Let's Encrypt | SSL Certificates |
| GitHub | Configuration/Settings, Public Container Registry |
| Docker Hub | Public Container Registry |
| hCaptcha | Bot Detection |
| Apivoid | IP Information |
| Grafana | Logs & Metrics Storage |
| Backblaze | Object Store & Application Backups |
Other vendors or open-source projects that we consume or utilize but do not have an ongoing external API or system connection to are not included in this list. For example, rclone is used to back up our platform, but it is integrated into a custom container image that is built and deployed. The availability of the application on its download site is not mandatory for the operational readiness of vmst.io.
Compute Resources
Virtual Machines
We use an all-virtual architecture using DigitalOcean "Droplets" as the compute backend for all our hosted services and databases.
Kubernetes
We use the DigitalOcean managed Kubernetes service.
Virtual machines are provisioned automatically by the control plane to be consumed as Kubernetes nodes. There are multiple nodes with 4 vCPUs and 8 GB of memory each. The total number of nodes can be scaled up or down based on overall demand.
All of the required Mastodon components are run in Kubernetes deployments, which create pods. Each pod is a Docker container running a given service (Puma, Sidekiq, etc.)
Required Components
The following reflect the required software components to have a functional deployment of Mastodon:
Mastodon
What users perceive as "Mastodon" is a Ruby on Rails application with a React front end, served by Puma. This provides the Mastodon API, web user interface, as well as ActivityPub federation.
The Streaming API is a separate Node.js application which provides a background WebSockets connection between your browser session and the Mastodon server to provide real-time "streaming" updates as new posts are loaded to your timeline.
Sidekiq
Sidekiq is a popular background job processing library for Ruby applications, and it is used in Mastodon for various purposes:
- Federated content delivery
- Push notifications
- Media processing
- Scheduled tasks
In the vmst.io environment, Sidekiq processes nearly two million tasks per day.
By default, deploying Mastodon generates a single Sidekiq service container with 5 threads. Each active thread can potentially establish a connection to the PostgreSQL database or perform other tasks, such as sending email notifications, fetching remote images, or notifying other servers of user posts. This behavior is somewhat unpredictable.
5 threads may suffice for a server with a few active users that experianced light light load. However, a single popular toot going viral can quickly cause queues to back up and timelines to stop updating until the backlog is processed.
It might be tempting to increase the number of threads in your Sidekiq service file from 5 to 25, 50, 100, etc. However, this is not the correct approach. Sidekiq will not properly utilize more than ~20 threads generated by a single service; you will simply consume CPU cycles and waste potential database connections.
The solution is to spawn more Sidekiq workers by creating additional systemd services or Docker containers dedicated to Sidekiq.
Each service should be limited to the queue(s) you want them to process in the order of their priority.
An explanation for the purpose of each queue can be found on docs.joinmastodon.org.
vmst.io has multiple Sidekiq processes running, with seperation of the workloads based on priority and to efficently process user requests.
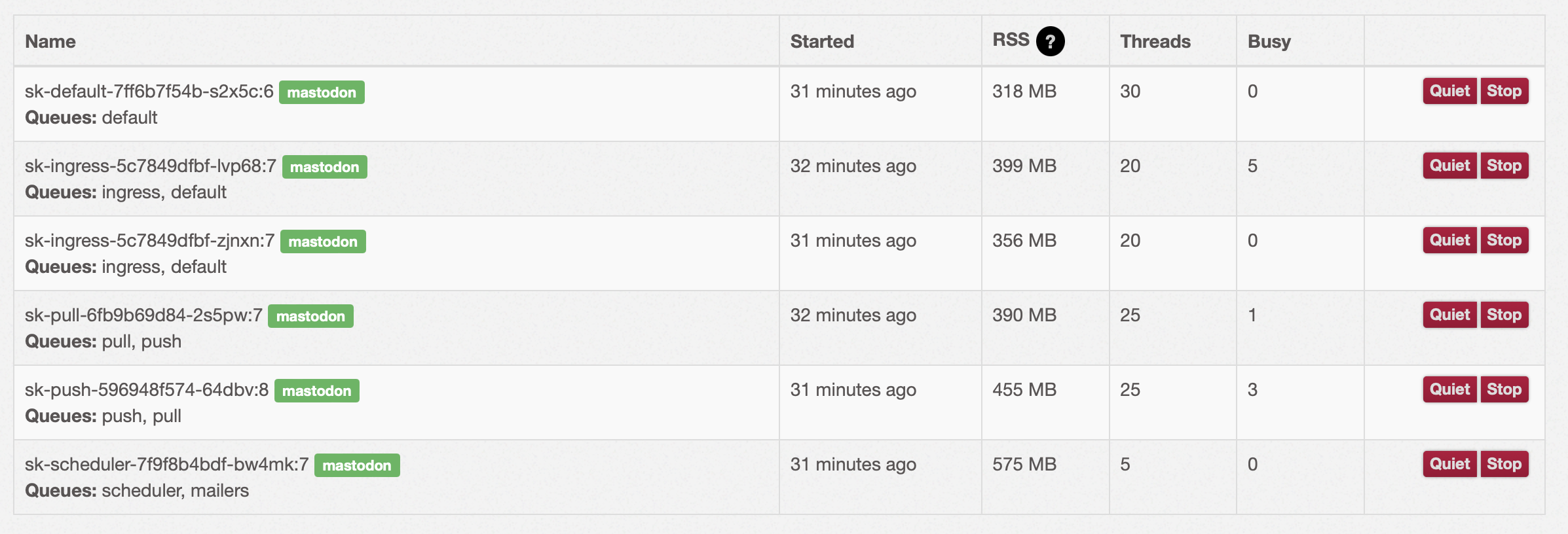
The exact number of processes and their assigned threads varies from time to time as workloads change.
PostgreSQL
PostgreSQL, often referred to as Postgres, is an open-source relational database management system. In Mastodon, it is used as the primary database to store and manage various types of data required for the functioning of the platform. PostgreSQL plays a crucial role in Mastodon's architecture, providing persistence, data integrity, and efficient querying capabilities.
We use the DigitalOcean managed PostgresSQL database service, which delivers a highly available database backend. Updates and maintenance are performed by DigitalOcean, independent of our administration efforts.
We have one database server (Majel) with 2 dedicated vCPU and 16GB of memory. We use PostgreSQL 17.x.
DigitalOcean Droplet "T-Shirt" sizes for databases are determined by vCPU, memory, disk size, and connections to the database. The connection count limits are based on sizing best practices for PostgreSQL, with a few held in reserve for their use to manage the service.
DigitalOcean has an integrated "Connection Pool" feature of their platform, which, in practice, puts the PgBouncer utility in front of the database. This acts as a reverse proxy / load balancer for the database, to ensure that connections to the database by Mastodon cannot stay open and consume resources longer than needed.
There are a few options for pooling modes with DigitalOcean, but the default Transaction Mode is the required option for Mastodon.
Redis
Redis is an open-source, in-memory data structure store that is used as a database, cache, and message broker. In Mastodon, Redis is used for various purposes to improve the performance, scalability, and reliability of the platform.
Starting in Mastodon 4.4, Redis forks (such as Valkey) or alternatives that implement the Redis API (such as Dragonfly) are supported for use.
We use the DigitalOcean managed Valkey database service, which delivers a highly available database backend.
We have one database server (Crusher) with 1 vCPU and 2GB of memory.
Updates and maintenance are performed by DigitalOcean, independent of our administration efforts.
Ingress
The idea of "ingress" covers the routing of inbound HTTP requests. We use DigitalOcean managed load balancer objects to distribute user traffic across our frontend reverse proxies.
We use Nginx as our reverse proxy software, running in our Kubernetes environment, in the form of the Ingress Nginx Controller.
Our Nginx reverse proxies provide TLS/SSL termination.
Additional Components
Most Mastodon deployments leverage one or more additional components to provide additional functionality.
Some of them include:
Elasticsearch →
On vmst.io we have full text search backended by our dedicated search indexing server (Khan) which is a cluster of three node 2 vCPU x 4GB RAM managed OpenSearch instance hosted at DigitalOcean.
Translation API →
DeepL is used as the translation API for our main web interface and client API. It is known for its accuracy and ability to grasp nuances in language better than many other translation services. For a list of languages that DeepL is able to process, please refer to their documentation.
DeepL is free for limited use, but we pay for the professional plan which has additional data security standards that delete requests from their servers after they are translated.
Object Storage
Object storage is a scalable and cost-effective storage solution that is used in Mastodon to store and manage large volumes of unstructured data, such as media files (images, videos, and audio) and static assets. In Mastodon, object storage plays a crucial role in efficiently handling and serving user-uploaded media content.
We use the DigitalOcean Spaces service, which is an S3-compatible object storage provider and includes a content delivery network (CDN) to distribute attached media to multiple points, reducing access latency for users and federated servers.
Our Spaces is in the DigitalOcean NYC3 data center, which is separate from the rest of the workloads which exist in the TOR1 (Toronto) data center.
SMTP Relay
All email notifications associated with the vmst.io Mastodon server should come from: [email protected].
- We use Amazon Simple Email Service as our managed SMTP service, used for sending new user sign-up verifications, and other account notifications.
- We leverage industry technologies like
SPFandDKIMto help verify we are the only ones sending you emails. - We use Fastmail for receiving and sending non-automated messages in the
@vmst.iodomain.
When you sign up for an account, and you provide us with an email address, we promise to only contact you there regarding your Mastodon account. For more details, refer to our Privacy Policy
Networking
The local IP space used between systems on our virtual private cloud (VPC) network is issued by DigitalOcean, with static IP addresses that are assigned at the creation of the Droplet and persist throughout the lifecycle of the virtual machines.
Where possible, any communication between internal nodes is encrypted even though the communication takes place on the VPC network.
There are a few cases where traffic leaves our VPC but still communicates within the DigitalOcean network, such as when data is moved between Droplets in Toronto and the Object Storage in NYC, or during replication between NYC and SFO data centers.
Public IPs
The public IP addresses assigned to our load balancer, CDN, and virtual machines are IP addresses issued and owned by DigitalOcean.
At this time, none of our systems are accessible via IPv6. This is due to a known limitation of DigitalOcean's managed load balancer service.
As the load balancer is our entry point for all other services, we do not enable IPv6 for Droplets even though it is technically supported.
DNS Resolution
We use DNSimple for our domain registrar and use DigitalOcean for our nameservers.
Security
In order to protect our users’ privacy and data, we implement a number of different security measures on our systems.
They include:
- Preventing unnecessary external access to systems through OS and service provider firewalls, and limiting communication between internal systems only to the source/destination ports and protocols required for functionality.
- Blocking any access to the system from known problematic networks.
- Leveraging an intrusion detection system to detect and deny access to active bad actors.
- Using updated versions—from trusted sources—of the source code and binaries downloaded to our systems.
- Requiring encrypted connections to all public facing elements, deprecating insecure ciphers, and using secure connections where possible—even on private networks—for communication between internal systems.
Certificates
We use Let's Encrypt as our primary certificate authority.